003. 딥러닝 공부 2일차 정리
어제 글을 작성안해서 글을 몰아서 작성하게 됬는데, 아무튼 오늘이 2일차다.
오늘 공부한 내용은 NLP의 기초? 와 같은 부분이다.
이미지는 픽셀값들을 정규화하고 특성맵을 추출하는 등의 방식으로 Classification이 가능했다.
(물론 과대적합을 방지하고 일반적인 상황에도 예측 성공률이 높도록 섞거나, 회전시키거나 하기도 하지만 )
그러나 언어는 이와 다르게 그런 방식으로 작동시키기 어렵다.
일단, 문자->숫자로 바꾸기도 쉽지가 않다.
ascii나 unicode와 같이 각 철자별로 정수로 바꿀 수 있지만, 이는 단어의 특성을 반영하기 어렵다.
그렇기 때문에, 단어를 통째로 묶어서 tokenize를 한다.
- I am a apple이 있다면 1:I, 2:am, 3:a, 4:apple 이런 식으로 많은 문장에 대해.
또한 토큰화된 문장마다 길이가 다를 수 있으므로 padding을 추가하여 길이를 맞추거나,
모델에 토큰화되지 않은 단어에 대해 OOV(Out-Of-Vocabulary) 토큰을 넣는 등의 가공을 하게 된다.
그렇게 뭐 어찌저찌 토큰화된 문장들을 만들었다고 해도 이것을 어떻게 분석을 해야하는지가 큰 문제다.
문장은 앞뒤 단어간 관계성이란 것이 있는데, CNN을 사용하던 수많은 Dense를 사용하던, 그 관계성을 나타내기란 어려울 것이다.
1. 양수와 음수 모델
예를 들어, 우리가 문장이 농담인지 확인하는 모델을 구현하기 위해, 각 문장에 농담 여부가 주어진 데이터셋이 있다고 하자.
이 때, 농담인 문장에 포함된 단어는 +1을 하고, 농담이 아닌 문장은 -1을 한다고 하자.
그러면 수만개의 문장에 대해 이 시퀀스를 동작하면 각 단어에 대해 얼마나 농담스러운 단어인지에 대한 점수가 매겨질 것이다.
이렇게 얻어낸 테이블을 가지고, 테스트 문장의 점수를 통해 농담인지 아닌지 추정하게 하는 모델이다.
2. 임베딩
어휘의 느낌에 대한 벡터값을 임의로 지정하고, 그렇게 계산된 결과가 일치하는지의 여부로 학습한다.
예를 들어 16개 차원에 대한 임베딩을 수행한다고 하면, 각 어휘에 대해 16차원 임의 벡터값이 지정되고, 이 벡터값들을 이용하여 문장이 농담인지 아닌지를 판별한다. ( 이 벡터값들에 대해 평균풀링, Dense 레이어 등을 거쳐서.. )
그러면 각 벡터값을 계속 변경해 가면서 문장의 농담 판별률을 가장 높일 수 있는 파라미터를 찾는다.
그러나 이런 임베딩 또한 언어의 성질로 인해 높은 정확도를 얻기는 어렵다. 정확히는, 과대적합이 일어날 가능성이 높다.
(문장을 이해해서 느낌을 파악한게 아니라, 단어들의 조합들로 알아낸 것이므로)
이로 인해 과대적합을 줄이기 위해 모델의 학습률을 줄이거나 (learning_rate 변화, 기본값 = 0.001), 임베딩에 포함될 단어의 개수를 늘리는 방식 (빈도가 높은 단어가 많이 포함될수록 과대적합이 일어남), L1,L2 규제를 이용하는 방식(큰 가중치를 작게 만드는)을 선택할 수 있다.
또한, 일반적으로 임베딩 차원은 어휘 개수의 네제곱근을 사용하는 것이라고 한다.
(20k개의 단어에 대해 12차원, 2k개의 단어에 대해 7차원...)
※ keras.layers.Embedding(vocab_size, dimension)
ex: keras.layers.Embedding(2000, 7)
3. RNN
그러나, 임베딩을 통해서도 결국 '어휘의 느낌을 통한 분석'일 뿐, 문장의 느낌을 알아내지는 못한다.
그리하여 등장한것이 바로 RNN, Recurernt Neural Network이다.
이를 통해 문장 내의 단어들로 관계성을 알아내 반영한다.
초기 RNN은 한 문장 내 거리가 가까운 단어 끼리의 관계성은 강하고, 먼 단어 끼리의 관계성은 약하게 분석했기 때문에 애로사항이 있었으나, LSTM(Long Short-Term Memory)의 등장으로 출력과 먼 위치의 정보도 기억하여 분석하게 되었다.
keras.layers.bidirection(keras.layers.LSTM(dim)) 으로 사용하며, dim은 Embedding에서 사용한 차원의 수와 맞춘다.
Embedding->Pooling에서는 임베딩 벡터가 그 단어의 뜻을 이해하는데 바로 사용되며, 단어마다 그 벡터의 값이 너무 작은 경우도 존재하므로 차원을 작게 잡지만, LSTM은 각 단어의 뜻을 가지고 문장을 분석해야 하는 만큼, 각 단어가 정보를 더 세밀하게 캡처하기 쉽도록 차원을 크게 잡아서 LSTM의 정확도를 높인다.
LSTM도 Dense 레이어를 사용하는 것 처럼 여러개를 적층시킬 수 있는데, 이 경우 마지막 LSTM만 Dense 레이어에 전달할 1차원 값으로 두고, LSTM 끼리는 시퀀스 정보를 주고받게 하기 위해 return_sequence=True를 인자로 주게 된다.
만약 LSTM의 return_sequence=False 출력값이 다음 LSTM의 입력값이 된다면, 문장의 각 단어의 느낌이 아니라, 이전 LSTM에서 추정된 값이 입력으로 주어지므로, 해당 LSTM에서의 분석은 좀 더 이상하게 될 것이고, 일부 정보는 손실되게 될 것이다.
이렇게 만들어진 모델도 과대적합이슈는 피할 수 없는데, 이 경우도 역시 학습률을 낮추거나 DropOut을 추가하는 방법을 주로 사용한다.
4. Pre-trained Embedding
드롭아웃을 늘리고, 학습률을 낮추고 하면 과대적합은 어느정도 잡히더라도 테스트셋에 대한 정확도가 쉽게 잡히지 않는다.
이는 우리의 어휘사전의 크기가 너무 작기 때문에, 각 어휘의 세밀한 느낌을 모두 잡아내지 못하기 때문이다.
이런 작은 개발자들을 위해 연구자들이 공유해준 사전 훈련된 임베딩을 이용하여 전이학습을 수행하는 방식이 있다.
이와 같은 임베딩들은 방금과 같이 2만개의 어휘 12차원 벡터 같은 작은 크기가 아니라. N십억개 이상의 토큰, N백만개의 어휘 사전, 100차원의 벡터와 같이 어마어마한 크기를 가지고 있다. 그렇기 때문에 문장을 구성하는 어휘의 느낌 분석의 정확도가 더욱 올라갈 것이고. 이를 통한 LSTM에서도 양질의 결과를 얻어낼 수 있을 것이다.
책에서는 GloVe pretrained model의 270억개 토큰, 120만개 어휘, 25차원 벡터 값을 공유한다. (아마 너무 높은 차원의 벡터를 이용하면 Epoch시간이 너무 길어져서 인 것 같다.)
이렇게 전이학습을 통해 모델을 구성하려고 하면, 다운 받은 모델의 weight 값들을 모아서 Embedding의 weight=에 넣어주고, trainable=를 False로 설정하여 학습이 완료됬음을 표시한다. 또한, 단어의 등장빈도를 파악하여 반영할 적절한 어휘의 개수를 찾아서 설정해주고, embedding_dim은 추가 학습이 없는 만큼, 가져온 전이학습 데이터의 차원(이경우 25차원)으로 설정해준다.
model = tf.keras.Sequential([
tf.keras.layers.Embedding(vocab_size, embedding_dim, weights=[embedding_matrix], trainable=False),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim, return_sequences=True, dropout=0.1)),
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(embedding_dim)),
tf.keras.layers.Dense(24, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# sigmoid는 출력된 값을 0~1 사이로 정규화 하는 활성화함수이다. (0% ~ 100%)
책에서는 dropout없이도 80 epoch쯤에서 과대적합이 일어났다고 했는데, 나는 거의 20번째 epoch에서 과대적합이 일어났었다. 그래서 과대적합을 막기위해 첫번째 LSTM에만 dropout을 10% 줘봤다.
기타 변수값은 vocab_size = 13200, embedding_dim = 25 이다.
30 Epoch로 학습을 시켰고, 각 Epoch는 약 13초가 소요되었다.

정확도는 0.7, loss는 0.57부근에서 수렴되었다.
책에서는 정확도 0.73, loss 0.55쯤에서 수렴하므로 어느정도 비슷한 모델이 되었다고 볼 수 있겠다.
그렇다면 이 모델은 신뢰성이 있을까?
아니다. 과대적합은 없지만 오버피팅되어있을 가능성이 있다.
그래서 신뢰성을 검증하려면 validation set이 있어야하지만, 책에서는 4개만 주어졌다.
이 4개에 대해서 실험을 해보자.
책에서는
test_sentences = ["It Was, For, Uh, Medical Reasons, Says Doctor To Boris Johnson, Explaining Why They Had To Give Him Haircut",
"It's a beautiful sunny day",
"I lived in Ireland, so in High School they made me learn to speak and write in Gaelic",
"Census Foot Soldiers Swarm Neighborhoods, Kick Down Doors To Tally Household Sizes"]라는 4개의 문장에 대해 빈정거리는 정도를 측정했다.
책에서 측정한 결과는 다음과 같다.
[[0.79484975]
[0.05374813]
[0.90637976]
[0.73468477]]내 측정 결과는 다음과 같다.
[[0.7348192 ]
[0.43601203]
[0.9058653 ]
[0.98514324]]대충 1,3,4번에 대해 높은 확률, 2번에 대해 낮은 확률을 매긴 것은 같으나.
내 모델은 2번에 대해 너무나도 모호한 결과가 나와버렸다.
그래서 50Epoch로 다시 학습을 시켜보았다.
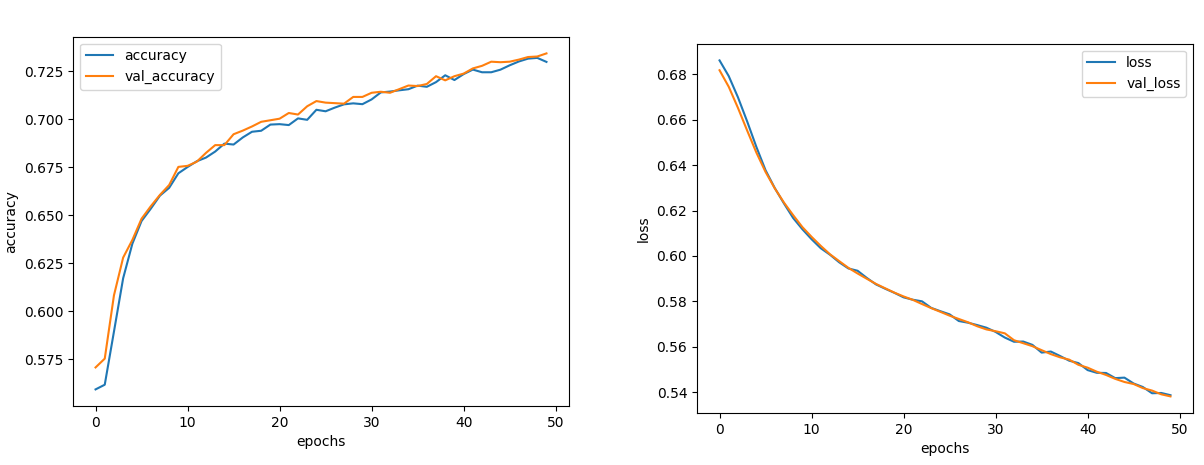
정확도는 0.73, 손실은 0.53쯤으로 수렴됬다.
[[0.6480013 ]
[0.15452237]
[0.8503598 ]
[0.8212178 ]]결과는 좀 더 정확해졌다.